一、选题的背景
目前互联网发达,各种搜索引擎各有千秋,对百度热搜的分析,可以直观地看出每个热点之间的差距,得出热点关系之间的联系,以及热点关键词的关系.
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称
《python爬虫之爬取百度热搜榜》
2.主题式网络爬虫爬取的内容与数据特征分析
爬取内容:"排名","热搜数据","标题"
数据特征分析:"排名"、"热度数据"的之间关系整体呈现上升的趋势,可通过后续绘制直方图、折线图等观察数据的变化情况。
3.主题式网络爬虫设计方案概述
实现思路:在浏览器 中通过F12访问网页源代码,,分析网站源代码,找到自己所需要的数据所在的位置,提取数据,对数据进行保存到相同路径csv文件中,读取改文件,进行数据清洗,数据模型分析,数据可视化处理,绘制分布图,用最小二乘法分析两个变量间的二次拟合方程和绘制拟合曲线。
技术难点:对库使用和库中函数的运用,爬取的内容的机构分析处理做数据分析,即求回归系数,因为标题是文字,无法与数字作比较,需要把标题这一列删除才可。由于不明原因,输出结果经常会显示超出列表范围。
三.主题页面的结构特征分析
1.主题页面的结构与特征分析:先寻找到热搜对应的网页代码,紧接着寻找排名,标题,热度数据所对应的class标签。
2.页面解析

1.
1 #输入所要爬取的网页 2 url="https://top.baidu.com/board?tab=realtime" 3 #伪装爬虫头避免被检测拦截 4 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62'} 5 #请求网站 6 r=requests.get(url) 7 #print(r.text) 8 #对页面内容重新编码 9 r.encoding=r.apparent_encoding 10 data=r.text 11 #使用BeautifulSoup 12 soup=BeautifulSoup(data,'html.parser') 13 #显示网站结构 14 #print(soup.prettify()) 15 head=[] 16 index=[] 17 for i in soup.find_all(class_="hot-index_1Bl1a"): 18 head.append(i.get_text().strip()) 19 for i in soup.find_all(class_="c-single-text-ellipsis"): 20 index.append(i.get_text().strip()) 21 data=[head,index] 22 s=pd.DataFrame(data,index=["标题","热度数据"]) 23 #将所得数据进行可视化 24 print(s.T)

2.
1 #将数据保存至本地并进行数据的清理 2 S="F:\各种工作杂碎东西\\baidu1.csv" 3 df=pd.DataFrame(data,index=["标题","热度数据"]) 4 df.T.to_csv(S,encoding="utf_8_sig")

1 #清洗数据 2 #有表头读入 3 df = pd.read_csv('F:\各种工作杂碎东西\\baidu1.csv') 4 #修改表头 5 df = pd.read_csv('F:\各种工作杂碎东西\\baidu1.csv',header=None,names=['排名','热度数据','标题']) 6 #调整排名 7 df=df.drop([0]) 8 for i in range(31): 9 df['排名'].loc[i] =i 10 df

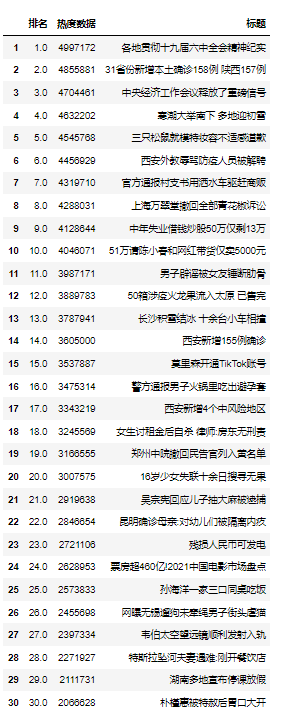
3.
1 #检查是否有重复值 print(df.duplicated())

4.
1 #检查是否有空值 2 print(df['热度数据'].isnull().value_counts())

5.
1 #异常值处理 2 print(df.describe())

6.
1 from sklearn.linear_model import LinearRegression 2 X = df.drop("标题",axis=1) 3 predict_model = LinearRegression() 4 predict_model.fit(X,df['热度数据']) 5 print("回归系数为:",predict_model.coef_)

7.
1 #绘制排名与热度的回归图 2 import seaborn as sns 3 sns.lmplot(x='排名', y='热度数据', data=df, ci=None)
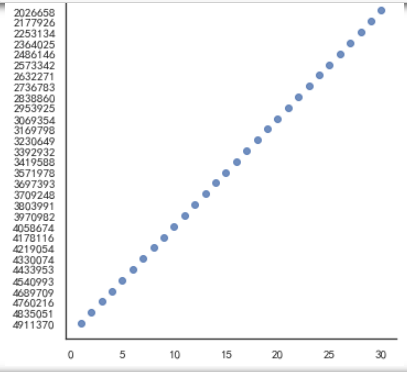
8.
1 import numpy as np 2 #画出散点图 3 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 4 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 5 N=100 6 x=np.random.rand(N) 7 y=np.random.rand(N) 8 size=50 9 plt.xlabel("排名") 10 plt.ylabel("热度数据") 11 plt.scatter(x,y,size,color='b',alpha=0.5,marker="o") 12 #散点图 13 sns.jointplot(x="排名",y="热度数据",data=df,kind='reg',color='g') 14 sns.jointplot(x="排名",y="热度数据",data=df,kind='hex',color='r') 15 sns.jointplot(x="排名",y="热度数据",data=df,kind="kde",space=0,color='bule')
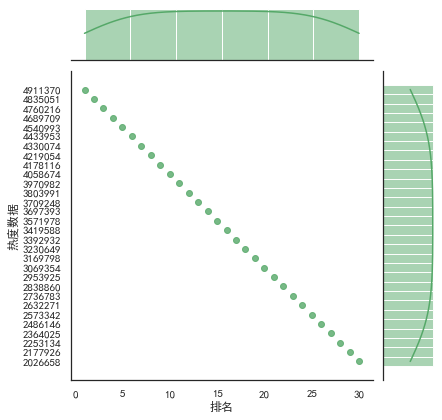

9.
1 import csv 2 import matplotlib.pyplot as plt 3 import pandas as pd 4 xdata = [] 5 ydata = [] 6 xdata = df.loc[:,'排名'] #将csv中列名为“列名1”的列存入xdata数组中 7 #如果ix报错请将其改为loc 8 ydata = df.loc[:,'热度数据'] 9 plt.plot(xdata,ydata,'bo-',label=u'',linewidth=1) 10 plt.title(u"折线图",size=10) #设置表名为“表名” 11 plt.legend() 12 plt.xlabel(u'排名',size=10) #设置x轴名为“x轴名” 13 plt.ylabel(u'热度数据',size=10) #设置y轴名为“y轴名” 14 plt.show()
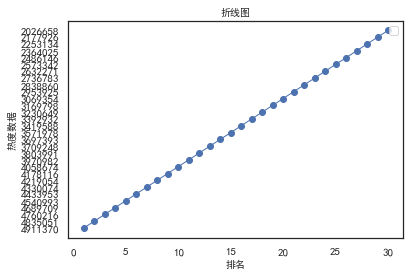
10.
1 #标题直方图分析趋势 2 import matplotlib.pyplot as plt 3 x = df['标题'].head(20) 4 y = df['热度数据'].head(20) 5 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 6 plt.rcParams['axes.unicode_minus']=False 7 plt.xticks(rotation=90) 8 plt.bar(x,y,alpha=0.2, width=0.4, color='b', lw=3,label="标题") 9 plt.plot(x,y,'-',color = 'r',label="热度数据") 10 plt.legend(loc = "best")#图例 11 plt.title("热搜指数趋势图") 12 plt.xlabel("标题",)#横坐标名字 13 plt.ylabel("热度数据")#纵坐标名字 14 plt.show()

11.
1 #标题水平直方图 2 plt.barh(x,y, alpha=0.2, height=0.4, color='red',label="热度数据", lw=3) 3 plt.title("热搜指数水平图") 4 plt.legend(loc = "best")#图例 5 plt.xlabel("标题",)#横坐标名字 6 plt.ylabel("热度数据")#纵坐标名字 7 plt.show()
12.
1 #绘画盒图 2 plt.xlabel("排名") 3 plt.ylabel("热度数据") 4 sns.boxplot(x='排名',y='热度数据',data=df)

13.
1 #标题云图 2 import pandas as pd 3 import numpy as np 4 import wordcloud as wc 5 from PIL import Image 6 import matplotlib.pyplot as plt 7 import random 8 9 bk = np.array(Image.open(r"C:\Users\12278\Desktop\无标题.png")) 10 mask = bk 11 # 定义尺寸 12 word_cloud = wc.WordCloud( 13 width=2000, # 词云图宽 14 height=1000, # 词云图高 15 mask = mask, 16 background_color='black', # 词云图背景颜色,默认为白色 17 font_path='msyhbd.ttc', # 词云图 字体(中文需要设定为本机有的中文字体) 18 max_font_size=400, # 最大字体,默认为200 19 random_state=50, # 为每个单词返回一个PIL颜色 20 ) 21 text = df["标题"] 22 text = " ".join(text) 23 word_cloud.generate(text) 24 plt.imshow(word_cloud) 25 plt.show()
1 #数据持久化 2 df = pd.DataFrame(df,columns=["排名","热度数据","标题"]) 3 df.to_csv('百度3.csv',encoding = 'gbk') #保存文件,数据持久化
四.完整代码
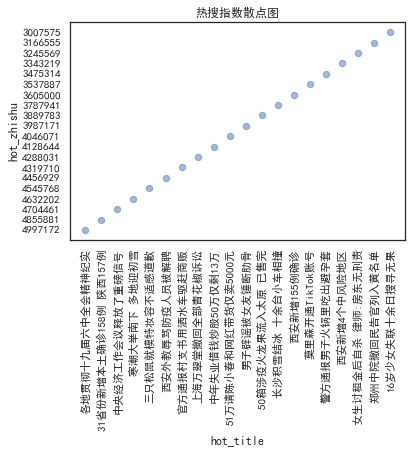
1 #输入所要爬取的网页 2 url="https://top.baidu.com/board?tab=realtime" 3 #伪装爬虫头避免被检测拦截 4 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62'} 5 #请求网站 6 r=requests.get(url) 7 #print(r.text) 8 #对页面内容重新编码 9 r.encoding=r.apparent_encoding 10 data=r.text 11 #使用BeautifulSoup 12 soup=BeautifulSoup(data,'html.parser') 13 #显示网站结构 14 #print(soup.prettify()) 15 head=[] 16 index=[] 17 for i in soup.find_all(class_="hot-index_1Bl1a"): 18 head.append(i.get_text().strip()) 19 for i in soup.find_all(class_="c-single-text-ellipsis"): 20 index.append(i.get_text().strip()) 21 data=[head,index] 22 s=pd.DataFrame(data,index=["标题","热度数据"]) 23 #将所得数据进行可视化 24 print(s.T) 25 #将数据保存至本地并进行数据的清理 26 S="F:\各种工作杂碎东西\\baidu1.csv" 27 df=pd.DataFrame(data,index=["标题","热度数据"]) 28 df.T.to_csv(S,encoding="utf_8_sig") 29 30 #清洗数据 31 #有表头读入 32 df = pd.read_csv('F:\各种工作杂碎东西\\baidu1.csv') 33 #修改表头 34 df = pd.read_csv('F:\各种工作杂碎东西\\baidu1.csv',header=None,names=['排名','热度数据','标题']) 35 #调整排名 36 df=df.drop([0]) 37 for i in range(31): 38 df['排名'].loc[i] =i 39 #清洗数据 40 #有表头读入 41 df = pd.read_csv('F:\各种工作杂碎东西\\baidu1.csv') 42 #修改表头 43 df = pd.read_csv('F:\各种工作杂碎东西\\baidu1.csv',header=None,names=['排名','热度数据','标题']) 44 #调整排名 45 df=df.drop([0]) 46 for i in range(31): 47 df['排名'].loc[i] =i 48 #清洗数据 49 #有表头读入 50 df = pd.read_csv('F:\各种工作杂碎东西\\baidu1.csv') 51 #修改表头 52 df = pd.read_csv('F:\各种工作杂碎东西\\baidu1.csv',header=None,names=['排名','热度数据','标题']) 53 #调整排名 54 df=df.drop([0]) 55 for i in range(31): 56 df['排名'].loc[i] =i 57 #检查是否有重复值 58 print(df.duplicated()) 59 #检查是否有空值 60 print(df['热度数据'].isnull().value_counts()) 61 #异常值处理 62 print(df.describe()) 63 X = df.drop("标题",axis=1) 64 predict_model = LinearRegression() 65 predict_model.fit(X,df['热度数据']) 66 print("回归系数为:",predict_model.coef_) 67 sns.lmplot(x='排名', y='热度数据', data=df, ci=None) 68 #画出散点图 69 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 70 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 71 N=100 72 x=np.random.rand(N) 73 y=np.random.rand(N) 74 size=50 75 plt.xlabel("排名") 76 plt.ylabel("热度数据") 77 plt.scatter(x,y,size,color='b',alpha=0.5,marker="o") 78 #散点图 79 sns.jointplot(x="排名",y="热度数据",data=df,kind='reg',color='g') 80 sns.jointplot(x="排名",y="热度数据",data=df,kind='hex',color='r') 81 sns.jointplot(x="排名",y="热度数据",data=df,kind="kde",space=0,color='bule') 82 xdata = [] 83 ydata = [] 84 xdata = df.loc[:,'排名'] #将csv中列名为“列名1”的列存入xdata数组中 85 #如果ix报错请将其改为loc 86 ydata = df.loc[:,'热度数据'] 87 plt.plot(xdata,ydata,'bo-',label=u'',linewidth=1) 88 plt.title(u"折线图",size=10) #设置表名为“表名” 89 plt.legend() 90 plt.xlabel(u'排名',size=10) #设置x轴名为“x轴名” 91 plt.ylabel(u'热度数据',size=10) #设置y轴名为“y轴名” 92 plt.show() 93 x = df['标题'].head(20) 94 y = df['热度数据'].head(20) 95 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 96 plt.rcParams['axes.unicode_minus']=False 97 plt.xticks(rotation=90) 98 plt.bar(x,y,alpha=0.2, width=0.4, color='b', lw=3,label="标题") 99 plt.plot(x,y,'-',color = 'r',label="热度数据") 100 plt.legend(loc = "best")#图例 101 plt.title("热搜指数趋势图") 102 plt.xlabel("标题",)#横坐标名字 103 plt.ylabel("热度数据")#纵坐标名字 104 plt.show() 105 #标题水平直方图 106 plt.barh(x,y, alpha=0.2, height=0.4, color='red',label="热度数据", lw=3) 107 plt.title("热搜指数水平图") 108 plt.legend(loc = "best")#图例 109 plt.xlabel("标题",)#横坐标名字 110 plt.ylabel("热度数据")#纵坐标名字 111 plt.show() 112 #标题散点图 113 114 plt.scatter(x,y,color='b',marker='o',s=40,alpha=0.5) 115 plt.xticks(rotation=90) 116 plt.title("热搜指数散点图") 117 plt.xlabel("hot_title",)#横坐标名字 118 plt.ylabel("hot_zhishu")#纵坐标名字 119 plt.show() 120 bk = np.array(Image.open(r"C:\Users\12278\Desktop\无标题.png")) 121 mask = bk 122 # 定义尺寸 123 word_cloud = wc.WordCloud( 124 width=2000, # 词云图宽 125 height=1000, # 词云图高 126 mask = mask, 127 background_color='black', # 词云图背景颜色,默认为白色 128 font_path='msyhbd.ttc', # 词云图 字体(中文需要设定为本机有的中文字体) 129 max_font_size=400, # 最大字体,默认为200 130 random_state=50, # 为每个单词返回一个PIL颜色 131 ) 132 text = df["标题"] 133 text = " ".join(text) 134 word_cloud.generate(text) 135 plt.imshow(word_cloud) 136 plt.show() 137 #绘画盒图 138 plt.xlabel("排名") 139 plt.ylabel("热度数据") 140 sns.boxplot(x='排名',y='热度数据',data=df) 141 #数据持久化 142 df = pd.DataFrame(df,columns=["排名","热度数据","标题"]) 143 df.to_csv('百度3.csv',encoding = 'gbk') #保存文件,数据持久化
四.总结
1.通过对数据的分析可以发现整体的热度是成一次函数形式上升的,并且热度值最高点与最低点之间相差300W之间,普通热点第一一般不会超过500W,最低热点也有200W以上。
2.小结:在这次对百度热榜的分析的过程中,我从中学会了不少函数及用法。很多次都卡在一个点上,绞尽脑汁去想解决问题的办法,通过观看b站的视频,百度搜索等方法去找寻答案。这两个星期来也养成了耐心和独立思考的习惯,并且提高了我对Python的兴趣。



